

Introduction
Onions and garlic are basic seasoning vegetables used in Korean cuisine and are closely related to people’s lives, but due to their supply and demand instability, their prices are highly volatile (Ha et al., 2019). In the case of onions and garlic, which require a wintering period for their growth, the long cultivation period and large fluctuations in cultivated area and production make it difficult for producers to predict the market at harvest time and to make rational decisions. The onion price collapse in 2022 is a representative case. As a result of the prolonged COVID-19 pandemic, consumer demand remained weak. Despite having a large inventory, the wholesale price of onions dropped from an average of KRW 1,900 per kg in 2020 to KRW 449 per kg in February 2021, due to the shipment of onions (Farmer’s Newspaper, 2022). Garlic suffered a similar drop in 2020, and farmers who fear a repeat of the situation are calling for active government measures. The government has included onions and garlic in the top five supply and demand management vegetables and is taking measures to stabilize their prices, such as suspending shipments and providing purchase subsidies (Ha et al., 2019). However, in order for supply stability policies to be effective, it is essential to design the policy based on accurate crop yield predictions.
The study of crop yield prediction takes into account various factors such as climatic conditions and technological advancements. This is because crop yields are sensitive to a range of factors including weather patterns and technological advancements such as pest control and cultivation techniques. (Han et al., 2011). Previous studies predicting crop yield can be categorized into those that do not consider technological development factors (Han and Kim, 2004; Hyun and Kim, 2021; Lee et al., 2021; Lim et al., 2016; Moon and Jung, 2021; Nam and Choi, 2015) and those that consider technological development factors (Ko and Kim, 2012; Lee et al., 2004; Han et al., 2011). Studies that consider technological development factors have used time trend variables as proxy variables in order to reflect most of the agricultural technology improvements. However, as climate risk in agriculture deepens due to climate change, time variable may not suffice to account for both the general technological improvement in our society and the increasing uncertainty of the environment.
To compensate for this issue, it is necessary to devise new proxies for technological development. Crop yields are likely to be affected by the accuracy of weather forecasts. This is because accurate weather information is essential for successful crop cultivation (Yang and Yoon, 2018). According to the Misintry of Government Legistration (2019), agricultural technologies (RA) are classified into 5 categories including Agricultural and Forestry Ecosystem and Environment category (RA04), in which the response to climate change (RA0406) is included. In simpler terms, the accuracy of weather information can significantly influence crop cultivation and management. With more precise weather forecasts, the risk of crop damage caused by unexpected weather changes decreases, allowing for more efficient crop management. In this regard, the accuracy of weather forecasting technologies can reflect the technology of cultivation, and therefore, it is necessary to verify whether the accuracy of weather forecasting can be utilized as a proxy for technological development.
This study aims to verify whether the weather forecast accuracy can be used as a proxy for technological development factors by using weather forecast accuracy in yield forecast model as a proxy for new technological development instead of a time trend variable. In this way, we extend previous research approaches and contribute to accurate supply and demand forecasting of onion and garlic.
We estimate the yields of onions and garlic on the accuracy of the precipitation forecast, which is measured by the Precipitation Hit Rate Index, using the random effects estimation method. The results show that the forecasting accuracy of precipitation, in the form of the product of total rain and accuracy rate, could be used to predict the yield of seasoning vegetables by replacing the time trend variable.
This paper is organized as follows. Section 2 describes the analytical model. Section 3 describes the data used in the analysis, followed by Section 4, which describes the results. Finally, Section 5 summarizes the findings and concludes.
Materials and Methods
To verify whether the weather forecast accuracy can be used as a proxy for technological development we apply Tack et al. (2012) empirical model which predicts agricultural output on input vectors such as weather and time. We substitute weather forecast accuracy for the time trend variable as a proxy for the technological development and build a yield forecasting model as follows.
The subscript i represents the region, t represents year (time), and y represents the unit production (onion yield or garlic yield). The terms Low, Med, and High pertain to the duration of different temperature conditions relative to the ideal temperature range for optimal vegetable growth. Low represents the number of days when the average daily temperature falls below the optimum temperature, Med signifies the number of days within the optimal temperature range, and High indicates the number of days when the average daily temperature exceeds the optimum level. Rain refers to total precipitation, which was calculated based on the length of time between the sowing and harvesting periods of each vegetable (the growing season) to convert these weather variables into yearly representative values. Specifically, onions were planted in between August and September of the previous year, and harvested within May and June, so weather information from September 2012 to June 2013 were used in the model. Garlic is generally planted around September and October, and harvested around May (Rural Development Administration; RDA). So weather information from September to May were summarized into yearly data. These variables represent the weather factors in the yield forecast model (Rural Development Administration). Accuracy refers to the accuracy of the forecast of the Korea Meteorological Administration (KMA) as a proxy for the technological development, and we compare the precipitation accuracy and the precipitation hit rate (detection index), which are indicators published by the KMA every year. A detailed description of these metrics is provided at the end of this section. Finally, the intersection variable Totalrain×Accuracy was created by multiplying the Totalrain term, which represents the total rainfall in a region by multiplying the accuracy rate to measure the different effects of Accuracy between regions that have had a lot of rain and those that haven’t.
The Agricultural Technology Center regularly monitors precipitation and average temperature to provide information and management measures to minimize damage when weather conditions are extreme. In particular, winter crops such as garlic and onions are vulnerable to drought, so it is necessary to thoroughly manage their growth according to weather conditions. Considering this, average temperature and precipitation were included in the model. On the other hand, the yield forecast model of Tack et al. (2012) includes a dummy variable reflecting the presence or absence of irrigation in the region to compare the effects of the explanatory variables with and without irrigation. However, this variable was not used in this study due to data limitations.
Panel data analysis is conducted using either fixed effects method or random effects method. In fixed effects, the influence of independent variables that vary over time is estimated, while in random effects, the influence of independent variables that do not change over time is estimated along with the influence of independent variables that change over time. The difference between the two methods is that in fixed effects, is considered as a parameter, while in random effects, is considered as a random variable. The choice between the two methods is typically determined through separate validation, and the Hausman test is commonly used for this purpose. The null hypothesis of the Hausman test is that there is no correlation between and independent variables. If the null hypothesis is rejected, the fixed effects is used, whereas if it is not rejected, the random effects is used. We selected the estimation method based on the results of the Hausman test. To account for any heteroscedasticity, we computed robust standard errors clustered at region level.
To evaluate the predictive power of the model, we adopt the root mean square percentage error (RMSPE) evaluation approach following Lee and Yang (2017). The RMSPE is a metric that converts the root mean square error (RMSE), whose value depends on the unit of measurement, into an intercomparable percentage unit. It can be noted as follows:
where, T is the number of time points to be predicted, is the predicted number of units, and is the actual number of units. Smaller value of RMSPE can be interpreted as better predicting power.
The data used in this study consists of three parts. First, regional vegetable production data from the Local Governments section of Korean Statistical Information Service (KOSIS) was used to determine the onion and garlic yields by region. The regions were selected based on the list of major production areas of each vegetable, which can be found at KOSIS. The 11 regions were selected as the major production areas for garlic and onion, respectively, excluding regions where they do not provide vegetable production data on KOSIS.
Second, the precipitation accuracy (PA) and precipitation hit rate (PHR) provided on the KMA’s Nuri homepage Prediction Evaluation section were considered as variables for the forecast accuracy of weather information by year. These indicators have been calculated and published since 2013 and have the limitation that they are calculated at the national level without specific regional distinctions. According to the official description file provided by KMA, the accuracy metric is calculated for the PA as follows:
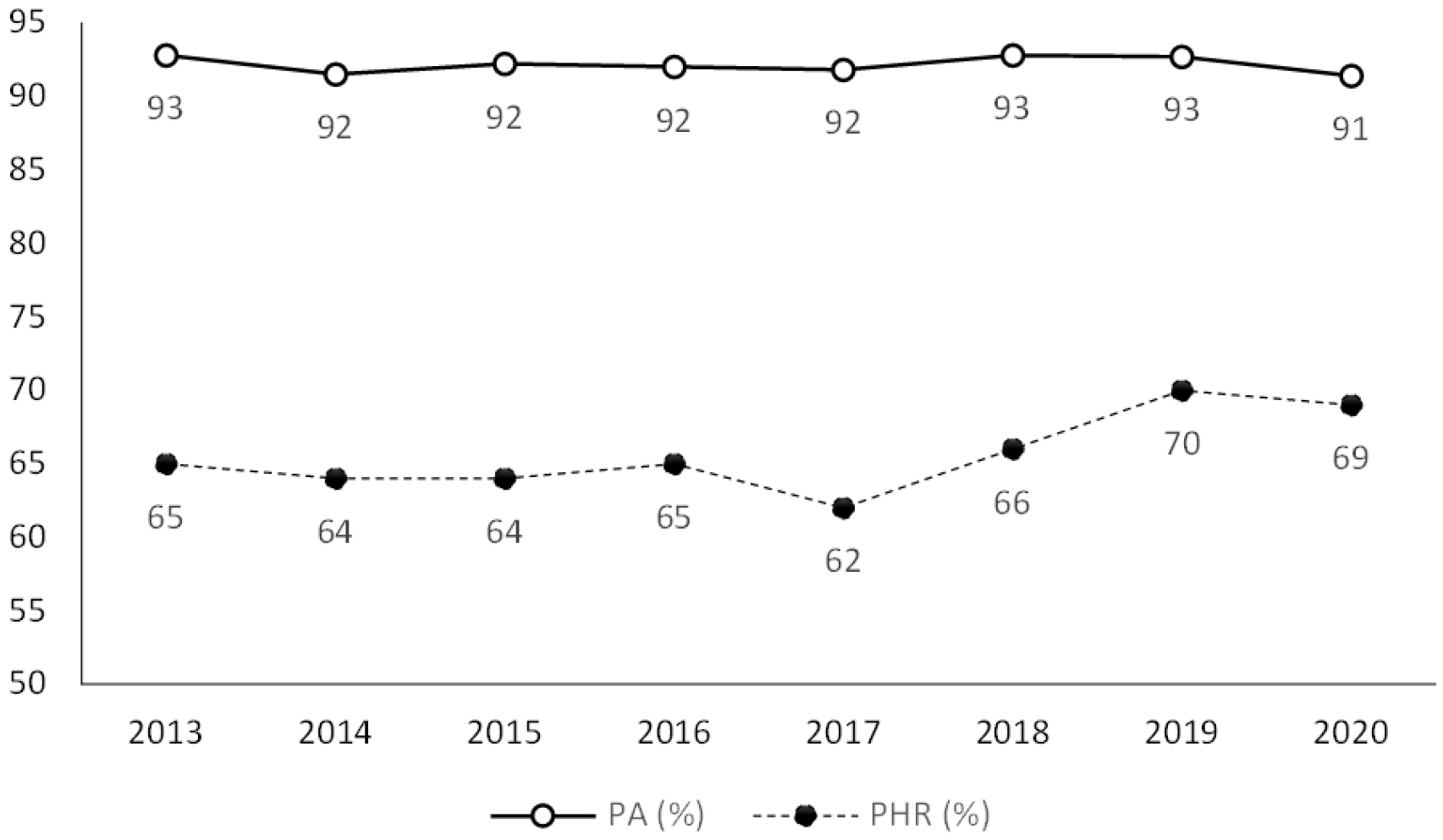
where H refers to the number of correct forecasting case after precipitation forecast, M refers to the number of rained case without precipitation forecast. F is the number of incorrect forecasting case after precipitation forecast, C is the number of not rained case without precipitation forecast. From the equation (3), we can see that the probability of precipitation is higher in regions where it does not rain often. This is because it is easier to avoid forecasting precipitation on sunny days than it is to predict actual precipitation. In Korea, where the number of days without precipitation is much higher than that of precipitation, the share of C in the accuracy calculation accounts for an average of 85.4% per year, so the accuracy does not decrease significantly even if H decreases or M or F increases. Therefore, in order to evaluate the prediction power more delicately, an indicator such as the PHR is also published. The calculation method of PHR is [H/(H+M)], which is an indicator that removes the influence of C which is inflated when calculating precipitation accuracy and F. Therefore, we use the PHR for the precipitation forecast accuracy variable, which is a more accurate representation of the weather forecasting power than the PA. Fig. 1. shows that the PA is always over 90%, but the PHR is only 70% in 2019 and has an improving trend recently.
Third, daily average temperature and precipitation data for each region were collected and utilized from the daily data obtained by Automated Synoptic Observing System (ASOS), provided in the KMA’s weather information website. In case of production areas without longitudinal observation stations, observations from the nearest city were used instead. Daily observations of temperatures are processed into dummy variables indicating whether the average temperature of the day belongs within each low (-14°C), medium (15°C-25°C) and high (26°C-) temperature range. This standard was based on the suitable temperature information for each crop provided by RDA official website (for onions 15°C-25°C, garlic 15°C-20°C). Then we counted the number of days within each range to use as explanatory variables Low, Med, and High for each city.
Upon merging the three datasets, we successfully compiled yearly data covering the period from 2013 to 2020 matching the time period of a given PHR. This combined dataset now encompasses information from all three sources for the specified time frame. The descriptive statistics of each variable used can be found in Table 1. The average unit yields of garlic and onion are 13.9 t/ha and 63.4 t/ha, respectively. There is a contrast in the average temperature between the garlic and onion production areas. The garlic production area experiences the most days within the optimal temperature range for growth, while the onion production area has the most days below this optimal temperature range. This is due to the fact that the onion growing season involves a longer overwintering period compared to that of garlic. The difference in the length of the growing season is also reflected in the annual precipitation, which is the total amount of rainfall per unit area.
Table 1.
Descriptive statistics
Source: Korean Statistical Information Service (KOSIS) and Korea Meteorological Administration (KMA) Weather Information Open Portal, Data obtained by Automated Synoptic Observing System (ASOS)(www.data.kma.go.kr)
Results
The model estimation results for onion and garlic are presented in Table 2 and Table 3, respectively. We select random effects estimation method because we can not reject the null hypothesis of Hausman Tests at 1% significant level in all models. Model (1) estimates regional unit production on Year to examine whether the unit yields of each vegetable is affected by time trend (a proxy used for technological progress in previous studies). Onion yields in column (1) of Table 2 shows a significant positive correlation with time trend, while garlic yields in column (1) of Table 3 shows no significant impact of the time trend.
Table 2.
Onion yield (kg/ha) estimation results
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | |
| Year |
857.6*** (307.8) |
78.87 (404.8) |
592.6* (350.6) | ||||
| Low |
87.84 (105.3) |
-108.7 (128.7) |
58.97 (104.1) |
-74.42 (118.8) | |||
| Med |
55.49 (164.6) |
-64.23 (191.9) |
-44.95 (164.1) |
67.82 (153.7) | |||
| High |
383.8 (515.0) |
-71.50 (579.1) |
565.4 (424.2) |
-6.451 (549.6) | |||
| Rain |
20.89 (16.64) |
23.37 (15.10) |
21.64 (14.67) |
19.51 (19.40) | |||
| Rain2 |
-0.00886 (0.0102) |
-0.0138 (0.00982) |
-0.00893 (0.00871) |
-0.0101 (0.0121) | |||
| Accuracy |
110,148*** (29,382) |
105,932*** (39,592) |
120,718** (48,241) |
132,032*** (43,791) | |||
| Totalrain×Accuracy |
0.0000009*** (0.0000003) |
0.0000009*** (0.0000003) |
0.0000010* (0.0000006) |
0.0000007 (0.0000004) | |||
| Constant |
-1,666,000*** (619,824) |
-11,856 (18,300) |
-168,082 (798,228) |
-1,165,000 (727,995) |
-1,208 (51,251) |
43,156 (39,162) |
-26,025 (46,052) |
| Obs | 81 | 81 | 81 | 81 | 81 | 81 | 81 |
| Number of region | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 0.053 | 0.252 | 0.252 | 0.100 | 0.278 | 0.201 | 0.184 | |
| Hausman Test [p-value] |
0.33 [0.564] |
6.02 [0.014] |
8.13 [0.017] |
3.32 [0.651] |
5.16 [0.396] |
4.6 [0.331] |
2.47 [0.781] |
| RMSPE | 0.143 | 0.125 | 0.125 | 0.138 | 0.122 | 0.131 | 0.130 |
Table 3.
Garlic yield (kg/ha) estimation results
| (1) | (2) | (3) | (4) | (5) | (6) | (7) | |
| Year |
16.34 (122.7) |
32.81 (85.17) |
-17.41 (111.2) | ||||
| Low |
-85.50 (80.22) |
-93.32 (81.37) |
-89.93 (88.04) |
-90.32 (72.10) | |||
| Med |
-104.3 (92.26) |
-112.7 (103.1) |
-114.2 (101.1) |
-101.4 (91.32) | |||
| High |
34.16 (101.1) |
0.393 (92.61) |
-0.744 (92.98) |
35.02 (105.7) | |||
| Rain |
2.588 (4.774) |
-6.954 (7.319) |
-6.456 (6.801) |
2.157 (5.002) | |||
| Rain2 |
-0.00305 (0.00388) |
0.00402 (0.00552) |
0.00376 (0.00527) |
-0.00300 (0.00388) | |||
| Accuracy |
800.5 (12,629) |
-1,191 (12,025) |
3,340 (15,733) |
4,272 (16,366) | |||
| Totalrain×Accuracy |
0.0000003* (0.0000002) |
0.0000003* (0.0000002) |
0.0000005** (0.0000002) |
0.0000005** (0.0000002) | |||
| Constant |
-19,024 (246,997) |
12,319 (7,929) |
-52,580 (171,162) |
61,104 (227,016) |
26,000 (19,417) |
27,917** (14,219) |
23,481 (18,100) |
| Obs | 82 | 82 | 82 | 82 | 82 | 82 | 82 |
| Number of region | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| 0.003 | 0.127 | 0.130 | 0.148 | 0.265 | 0.264 | 0.157 | |
|
Hausman Test [p-value] |
1.39 [0.238] |
0.07 [0.797] |
1.83 [0.401] |
7.24 [0.203] |
2.25 [0.814] |
2.24 [0.692] |
8.36 [0.138] |
| RMSPE | 0.240 | 0.220 | 0.219 | 0.229 | 0.215 | 0.214 | 0.230 |
In model (2), the variables Accuracy and Totalrain×Accuracy were used instead of the time trend variable. The results show that both variables with Accuracy are significant in the onion yields estimation result, replacing the time trend in model (1). In garlic model (2), Accuracy was not significant, but the positive coefficient on Totalrain×Accuracy was significant, suggesting that the region with more amount of precipitation has impacts of Accuracy on garlic yields while there is no impact of the time trend on garlic yields. The coefficients on Totalrain×Accuracy variable is small for both vegetables, but the coefficient of the Accuracy in the onion model (2) suggests that a 1% increase in the Accuracy increases onion unit yield by 110 t/ha. It is also noteworthy that the R-squared (the goodness of fit) of the model increases by 0.20 when replacing the time trend variable with the accuracy variables.
Model (3) includes both the time trend variable and accuracy variables, we can see that there is no big difference in the R-squared and significance of the coefficients for the onion and garlic models. This suggests that the variables Accuracy and Totalrain×Accuracy are sufficiently capturing the effects of the time trend in both vegetable yields.
Models (4), (5), (6), and (7) compare the impact of time trend, Accuracy and Totalrain×Accuracy when weather variables are controlled in the model. However, all weather variables controlled in the model were not significantly estimated. The R-squared value of model (5) for onion is the highest among all models, and model (5) for garlic is one of the highest as well.
Finally, model (6) excluded Accuracy and used only Totalrain×Accuracy while model (7) the opposite. The results showed that Accuracy variable is significant for onion yields while Totalrain×Accuracy is significant for garlic yields.
To evaluate the predicting power of each model, we compare RMSPE and values. In accordance with our interpretation of the coefficients, model (5) with both Accuracy and Totalrain×Accuracy has the best predicting power with the smallest RMSPE values of 0.122 for onion yields, while model (4) with time trend displayed the worst value. This suggests that using the accuracy variables as a proxy for technological development factors should be considered when forecasting onion yields and it may reasonably substitute the time trend variable, which is also the case for garlic. For garlic yields, model (6) has the best predicting power with the smallest RMSPE values of 0.214, while model (4) with time trend also displayed the worst predicting power.
Discussion
Previous studies on agricultural product yields forecasting have utilized a time trend as a proxy for technological development. This study analyzed whether the forecast accuracy of precipitation, which is potentially related to agriculture production, can be used as a better proxy for technological progress. The results show that the forecasting accuracy of precipitation, in the form of the product of total rain and accuracy rate, could be used to predict the yield of seasoning vegetables by replacing the time variable. We found that using the accuracy variables as a proxy for technological development factors should be considerable when forecasting onion and garlic yields and it may substitute the time trend variable and gain better predicting power.
On the other hand, due to data limitations, it was not possible to use a more specific precipitation prediction index, and as a result, the variation in precipitation prediction by region was small. In addition, the data used in the analysis did not include information on the varieties of each vegetable, so the difference in the growing process of each variety could not be reflected in the model. Also, only the regions where data were available (11 regions for onions and garlic) were used among the main producers of each vegetable, which is also an area that needs to be supplemented through future research. Finally, it is unfortunate that the variable of irrigation status, which has been shown to have an important impact on the prediction of shortages in previous studies, was not included.
Nevertheless, the contribution of this study is that it shows the indicator of accurate weather forecasting power can be used as a proxy for technological development in yield forecasting models. We hope that future studies will be able to further develop the yield forecasting model through more diverse attempts.
