

Introduction
Materials and Methods
Plant materials
Artificial Intelligence Model
Performance metrics
Results and Discussion
Introduction
Automatic classification of agricultural products has become possible owing to recent advances in digital image processing technology. Visual methods are subjective and influenced by the observer’s psychological state, so more accurate and objective image processing is needed. Research on image classification neural network models in agricultural fields has been on the increase, and is expected to help in the efficient production and management of agricultural products (Elnemr, 2019; Han et al., 2020; Kalaivani et al., 2022; Milioto et al., 2018; Moon et al., 2020; Purwaningsih et al., 2018; Samiei et al., Sandeep Kumar et al., 2018; Yang and Xu, 2021). Seedling classification has become extremely important in precision agriculture. Accurate classification is crucial due to competition with the same or other plants for nutrient, water, and sunlight. Especially, classification of weeds among crops and their early removal can improve crop productivity and quality (Elnemr, 2019; Milioto et al., 2018; Sandeep Kumar et al., 2018).
Although efforts have been made to use neural networks to remove unwanted vegetation, Convolutional Neural Networks (CNNs) are widely used as an efficient method in artificial intelligence technologies. CNNs extract features from data to identify patterns; they are one of the methods that can be used for image processing; and they are commonly used for analyzing visual images. The network consists of multiple layers, such as convolutional, pooling, and fully connected layers. Convolutional layers use filters to perform convolution operations on the input images and extract specific features; pooling layers then reduce the size of the image while maintaining its important features; and fully connected layers combine the extracted features to classify the image. CNNs extract features from input images through multiple convolution and pooling operations. Convolution operations use the filters of a specified size to multiply the filter and input image at regular intervals and sum the results. This process extracts the features that occur in specific parts of the input images. Pooling operations reduce the image size while providing invariance to changes in the image location and reduce computation. These extracted features are then connected through fully connected layers to obtain the final classification result. This structure is highly effective for image recognition because of the series of steps required to extract the image features. This technology has been used for classifying weeds (Elnemr, 2019; Milioto et al., 2018; Sandeep Kumar et al., 2018), classifying vegetables and flower seedlings(Xiao et al., 2019), predicting the biomass of red chili peppers (Moon et al., 2020), classifying tomato diseases (Han et al., 2020) and strawberry pests and diseases (Choi et al., 2022), classifying plant seed images (Kalaivani et al., 2022), and predicting the number of days until lettuce cultivation (Baek et al., 2023). In the early stages of seedling growth, image classification based on object recognition can significantly impact seedling development. Therefore, early classification during growth is crucial. Classifying crops can be challenging, especially when they grow together. In this study, a seedling classification model was established using transfer learning based on convolutional neural networks. Seedling samples were collected, and the established model was trained and tested to conduct the research.
Precision, recall, and F1 score are metrics used to evaluate the performance of classification models (Kumaratenna and Cho, 2024). Precision measures how accurate the positive predictions of the model are, recall measures the number of actual positive observations correctly identified by the model, and F1 score balances the precision and recall to provide an overall evaluation of the model performance. Therefore, we selected an optimal neural network model for the classification of nine vegetable seedling images and evaluated its precision, recall, and F1 score.
Materials and Methods
Plant materials
Nine vegetable species were used for image classification: they include carrot (Dream7, Danong Co., Korea, Kimchi cabbage (Asia Mini F1, Asiaseed Co., Korea), kohlrabi (Greenkohl, Asiaseed, Korea), lettuce (Summer Cheongchukmyeon, Jeliseed Co., Korea), mallow(Asia Chi Ma, Asiaseed Co., Korea), mustard (Jeil Cheong, Jeliseed Co., Korea), pak-choi (Jeil, Jeliseed Co., Korea), spinach (Susilo, Asiaseed Co., Korea), and sweet pepper (Volidano, Enxa Zaden, Australia). A total of 868 plant images were obtained using mobile phones (iPhone 12 Pro, SE2, 8, iPhone, USA and Galaxy S22, Samsung, Korea) from the time the vegetable leaves appeared. The images were classified into nine labels, as shown in Fig. 1.

Artificial Intelligence Model
Eight artificial intelligence models were used: they include DenseNet201, InceptionResNetV2, InceptionV3, MobileNetV2, ResNet152V2, VGG16, VGG19, and Xception. All the models were trained using a transfer learning approach with a 224 × 224 pixel input resolution. Using data augmentation techniques, the model training was enhanced, and these transformation methods significantly expanded the dataset, thereby improving the model’s performance. To select the best model, model accuracy was used as a criterion to minimize the root mean squared error (RMSE) between the estimated and actual values. Since it exhibited the highest accuracy under the conditions of 20 epochs, 32 batch size, Adam optimizer, and a learning rate of 0.001, all models were analyzed under the same parameters. Python language (ver 3.8.8) was used to write the code for this experiment, and various libraries such as TensorFlow, Numpy, Pandas, and Keras were used.
Performance metrics
In this study, three performance evaluation metrics, such as precision, recall, and F1 score, were used to select the optimal model and assess its performance. Each metric is presented vertically, and the formula is provided in (1), (2), and (3), respectively.
Precision represents the number of true positive labels when positive labels are provided. Recall describes the number of correctly labeled positive instances. F1 score considers both precision and recall to measure the overall performance of the model. True positive (TP) represents cases in which the true answer is predicted as true; false positive (FP) represents cases in which the false answer is predicted as true; false negative (FN) represents cases in which the true answer is predicted as false; and true negative (TN) represents cases in which the false answer is predicted as false.
Results and Discussion
In this study, 868 vegetable images were classified using eight different artificial intelligence models, and experiments were conducted. Results showed that DenseNet201, InceptionV3, MobileNetV2, ResNet152V2, VGG16, and Xception models exhibited high accuracies of over 80%. Among them, DenseNet201 model showed the best learning results with an accuracy of 90.5% (Table 1). These results were obtained under the same conditions (epochs, batch size, optimizer, and learning rate) for all models.
Table 1.
Analysis of classification accuracy of eight convolutional neural network models
| Model | Precision (%) | Model | Precision (%) |
| DenseNet201 | 90.5z | ResNet152V2 | 82.5 |
| InceptionResNetV2 | 78.3 | VGG16 | 80.8 |
| InceptionV3 | 82.3 | VGG19 | 67.6 |
| MobileNetV2 | 85.0 | Xception | 80.9 |
Kalaivani et al. (2022) reported that the optimization of hyperparameters such as batch size, optimizer, and learning rate for VGG19 and ResNet101 models is needed to achieve a performance that exceeds that of CNN in classifying 12 plant species. Gupta et al. (2020) used ResNet50, VGG16, VGG19, Xception, MobileNetV2, and CNN models to classify 12 plant species and found that ResNet50 achieved an accuracy of 95.23 %. However, in this study, hyperparameters were not optimized for models other than InceptionResNetV2 and VGG19, because all the models showed an accuracy of 80% or higher.
Densely Connected Convolutional Network (DenseNet) achieves better performance with fewer parameters than ResNet and Pre-Activation ResNet (Huang et al., 2018). In particular, the DenseNet201 model used in this study consisted of a CNN with 201 layers. It consists of five Dense Blocks and two transition layers (Fig. 2), and the input image size is 224 × 224 pixels.

DenseNet introduces the concept of a Dense Block for pooling operations, and it is composed of multiple layers, with pooling operations performed between Dense Blocks. The BN, 1 × 1 conv, and 2 × 2 avg_pool operations used for this purpose are called the transition layers. DenseNets offer several advantages by alleviating the vanishing gradient problem, enhancing feature propagation, encouraging feature reuse, and reducing the number of parameters. Hence, they can achieve high performance with fewer computations and significantly improve performance more than recent technologies do (Huang et al., 2018).
Elnemr (2019) classified 12 types of crops (three crops and nine weeds) and evaluated the results using accuracy, precision, recall, and F1 score. These evaluation metrics were also used in the present study. The DenseNet201 model exhibited high accuracy (Table 2) with a precision of 92%, a macro-average F1 score of 91%, and a weighted-average F1 score of 92%.
Table 2.
Performance metrics of the DenseNet201 model
For all vegetables classified using the DenseNet201 model, the precision and recall values were at least 88% and 81%, respectively, with cauliflower having the lowest precision and spinach having the lowest recall. The F1 score was above 86% for all vegetables. These results were attributed to the high precision, recall, and F1 score achieved by the DenseNet201 model when classifying vegetable images. Gupta et al. (2020) reported high precision, recall, and F1 scores for the VGG16 and ResNet50 models used for classifying 12 plant species and selected the ResNet50 model because it showed a higher validation accuracy than VGG16.
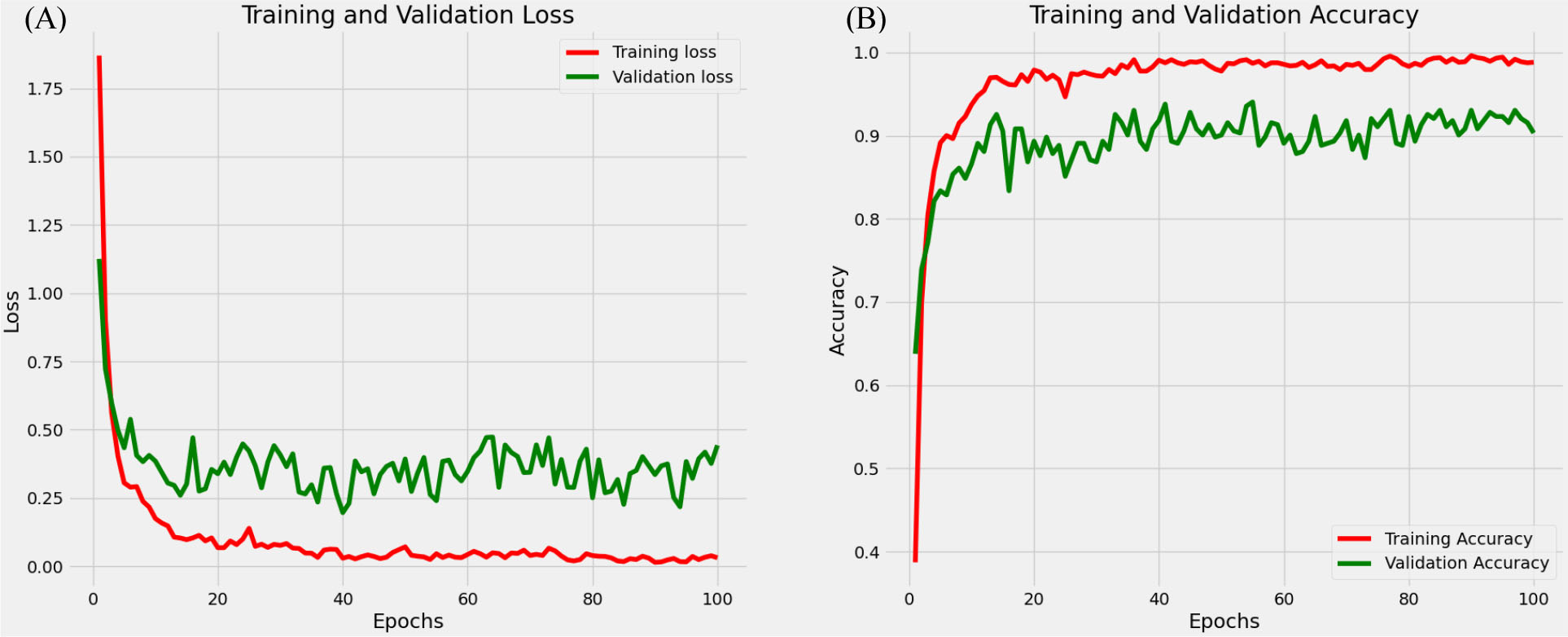
According to Fig. 3, the error and accuracy of the DenseNet201 model showed a decreasing and an increasing trend, respectively from epoch 2 onwards. There was no change in the error or accuracy when training was performed for more epochs, from 20 to 30. Additionally, a batch size of 128 yielded higher precision, recall, and F1 scores than a batch size of 32 (data not shown).
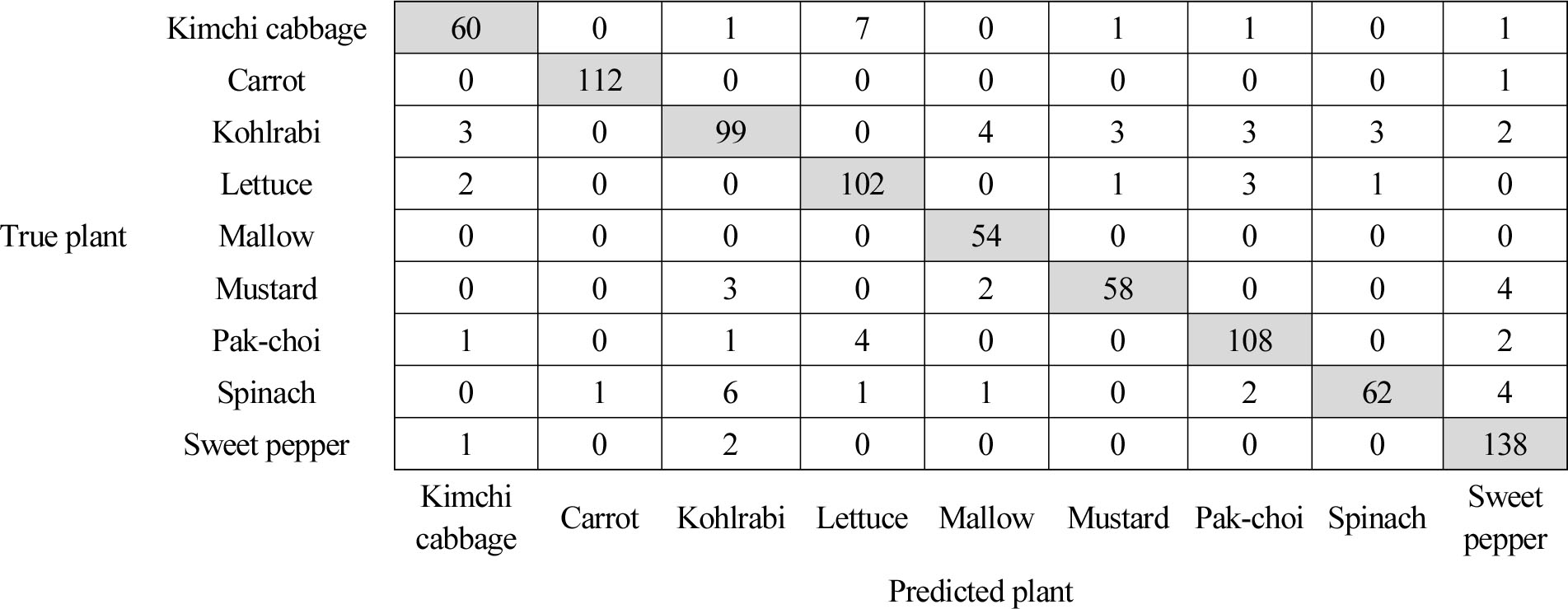
On examining the confusion matrix (Fig. 4) for crop classification, it was apparent that the predicted values of the model matched the actual results well for each crop. In general, a good model’s confusion matrix has high values on the diagonal, and in this study, the high diagonal values indicate that the predictions of the models were accurate. However, when inspecting the cases in which the model made four or more incorrect predictions, cabbage was frequently misclassified as lettuce, cauliflower as mugwort, mustard as red pepper, watercress as lettuce, and spinach as cauliflower or red pepper.
According to Yang and Xu (2021), 33.8% of deep learning technology applications in the field of horticulture from 2016 to 2021 are for species and variety classification. Artificial intelligence (AI) technology has been widely used for plant classification, and a CNN-based classification using images has shown a high accuracy of 92.96%. Elnemr (2019) reported an accuracy of 94.38% using CNN classification technology that can distinguish between three crops and nine weeds. Such a classification technology can be useful for crop management, and it is expected to be developed in the future to classify various types of crops. This can be very helpful in crop production, especially in the direct removal of weeds without having to harm the crops or apply herbicides. Therefore, these technologies are expected to play critical roles in agriculture. Sandeep Kumar et al. (2018) reported that crop productivity is significantly affected by weed control. Weeds compete with crops for nutrients, water, and light, consequently resulting in reduced crop yields, which negatively affects crop productivity (Elnemr, 2019); therefore, weed removal is crucial. Thus, it is believed that a quick classification of weeds and crops could help to improve crop productivity. According to Sandeep Kumar et al. (2018), convolutional neural networks can differentiate weeds from carrots with 95% confidence. However, the efficiency and accuracy of weed detection remain an issue, and the application of deep learning technology is necessary to solve this problem. Additionally, by using time-based image classification technology, it is possible to monitor the development and vitality of seedlings at low cost (Samiei et al., 2020) and determine their quality. This technology can also be used to continuously manage farms at various growth stages (Elnemr, 2019; Milioto et al., 2018; Yang and Xu, 2021). CNNs require a large amount of labeled data to perform well. If the dataset is small or lacks diversity, the CNN may not generalize well to new or unseen examples. In this study, 868 images were used, but it is determined that more images are needed to increase accuracy. In addition, it is necessary to expand the study from nine vegetable crops to more vegetable crops.
In this study, 868 images across 9 classes were obtained and classified using artificial intelligence techniques. Despite the limited number of images, they were successfully utilized for training, thanks to the application of data augmentation techniques. Data augmentation is a technique that increases the quantity of data by utilizing geometric transformations and task-based transformation methods. Geometric transformations involve altering the geometric properties of image data, such as resizing, flipping, cropping, and rotating, to expand the dataset. Task-based transformation methods focus on specific objects for recognition, utilizing techniques like cutting and flipping to extend the dataset (Choi et al., 2022; Shorten and Khoshgoftaar, 2019).
This study proposed a DenseNet201 model for object recognition based on images of vegetable seedlings. The model was designed for use in horticulture, and the goal was to improve its recognition performance by collecting more diverse object images of various plant species in the future. To achieve this, more networks will be applied, and high recognition accuracy would be achieved through hyperparameter optimization. We hope that this will contribute to the improvements of agricultural productivity.
